
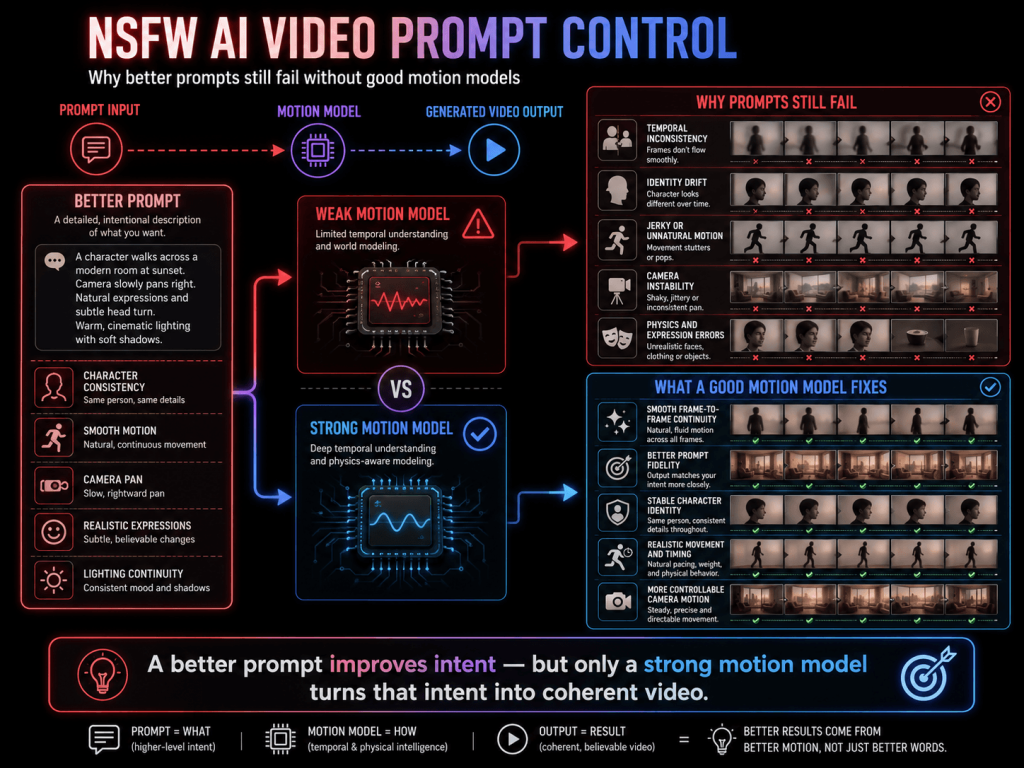
AI video generation has revolved rapidly, but even elaborate prompts have not helped many generate stable, realistic results. This problem is worsened in NSFW AI video generation, where the realism of movement, stable anatomy, and character consistency are key concerns, unlike in static images.
There is a widespread misconception that poor results are the result of an unimpressive prompt. This is rarely the case. A significant portion of the quality of AI video generation results is based on a model’s understanding of movement, temporal consistency, and the ability in AI video prompt control frames and camera.
No matter how well-phrased a prompt is, a video generation model that lacks a good motion model will fail to generate good-quality frames.
Why Video Generation Prompts Are Harder than Image Generation Prompts
Video generation prompts are harder because of the requirements of stability and continuity in video frames.
Image generation is much easier. A good image generation model must create one clear and visually notable image frame. A good video generation model, on the other hand, must create hundreds of frames that must:
- maintain consistent facial structures
- preserve body proportions
- keep clothes looking the same
- ensure the same lighting in all frames
- maintain the same perspective for the camera
- keep the same background
- move naturally throughout
A single frame may very well look nice on its own, but once it is part of a moving sequence, many problems may quickly arise:
- textures that flicker throughout the video
- faces that drift
- lighting that changes throughout the video
- The background suddenly changes
In these cases, the issue is not the prompt. The major problem is the lack of understanding of temporal effects within the model.
The Problem of Consistency throughout the Video
The ability of AI systems to consistently control the visual aspects from frame to frame is termed temporal consistency.
AI-generated videos without proper temporal consistency often appear to be unstable and unnatural. Errors frame-to-frame become very apparent during motion.
Examples of temporal consistency failures:
- Frame-to-frame facial alterations
- Backgrounds and Skin glitches
- Objects disappearing.
This is one of the greatest technical challenges in modern AI video systems. This issue persists in even the most highly advanced nsfw AI video prompts as long as the model lacks an advanced motion architecture.
To enhance temporal stability newer versions use:
- Optical flow guidance
- Temporal attention layers
- Motion conditioning
- Multi-frame diffusion
- Latent consistency models
The Relation Between Motion Strength And The Result
In most AI video systems, motion strength determines the quality of the video.
Low motion strength tends to yield:
- Enhanced facial and textual coherence
- Most AI systems favor low motion strength.
- High motion strength tends to lead to:
- Frame flickering
- Identity drift
- Anatomical corruption and
- Camera drift.
These effects of high motion strength lead many experienced creators to favor a lower motion strength focus.
Creation of an effective AI video motion prompt requires knowledge of the optimal intensity of motion and an understanding of the flexibility AI systems have when resembling real-world controlled motion.
These prompts do not involve high variability and are therefore more likely to yield positive results like:
- Panning
- Dolly
- Body-controlled movement
- Rotational and Translational movement
Most AI systems are beyond the reasonable limits of control when prompts demand high movement.
Why Character Identity Breaks Across Frames
Maintaining consistency of character identity is one of the most demanding and least effectively solved problems of AI video generation.
Typically, an element in a scene may appear impeccable in just one instance, only to begin altering its look as the frames progress.
Common identity deficiencies include:
- Variation in facial features
- Changes to hair, eyes, or skin
- Shifts in body size or shape
The main reason for this is that a lot of the AI video generation systems still create frames based on probabilities rather than maintaining a consistent 3D model of the character.
However, evolving generation systems are attempting to find a breakthrough by:
- Conditioning reference images
- Character embeddings
- LoRA identity systems
- Multi-frame memory
- Face-locking systems
However, it is still a challenge to achieve identity coherence in long-form video generation.
The Importance of Camera Control
One of the most underrated factors in AI video generation is the handling of the camera direction.
Most of the problems regarding realism arise from the camera behaving in an unstable and/or unrealistic manner, not due to the weakness in the quality of the image.
Some of the camera issues include:
- Dramatic changes to Zoom
- Unpredictable camera positioning
- Depth issues
- Problems with the camera’s focal length
- Broken perspective
Effectively controlling the camera involves the provision of precise instructions to the AI systems, which is usually the case with strong prompts.
To achieve a “medium shot” style of prompt, the camera should be controlled from a distance.
In many cases, less control over the camera’s movement yields more realistic results than prompts involving over-dynamic camera control.
Tradeoff Between Stability and Detail
In the realm of video generation, it is believed that the quality of the outputs improves as the length of the prompts increases; this is often incorrect.
Excessive detail in the prompts requires the AI model to consider a multitude of variables, which include:
- Textures
- Lighting
- Movement
- Details
- Consistency
The more rules you implement, the more difficult it is to achieve temporal consistency.
This is the reason why precisely stated, short prompts, generally, surpass large written paragraphs.
The Safer Prompt Framework for Creator Workflows
As with many AI creations, the video models used for this purpose appear more responsive to the focus of the user’s workflow rather than the excessive complexity of AI video motion prompts.
Develop Initial Character Design
Have the same character live through all the prompts, keeping major edits to a minimum.
Focus on specific edits to:
- Hair
- Clothing
- Lighting
- Camera Position
Implement Simple Character Motion
Have characters perform:
- Slow Motion
- Simple Poses
- Small Edits
- Focus on adding complexity to the edits.
Create Simple and Separate Instruction Edits
Instruct the machine to do one of the following:
- Slowly move the camera.
- Maintain a fixed position.
- Add a dolly movement.
- Perform a combination of movement instructions.
Ensure Temporal Neutrality
Focus on consistency of:
- Facial Features.
- Character Structure.
- Lighting.
- Background.
Consistent motion of background and foreground contents is more important than adding visual detail to the design.
Add Complexity in a Controlled Fashion
Once a design is rendered stable, the following can be safely added:
- More characters.
- More complex environments.
- Increased velocity of design.
- Dynamic lighting.
- Longer clips.
This was more reliable than bringing complexity to the design.
The Future of AI’s Creation of Video
For AI to create still and moving images, increasing the length of prompts is not the goal. More advanced and complex movement systems will be the goal. For NSFW AI video prompt creators, understanding these technical challenges is mandatory.
Even the best-phrased prompt will not solve the problems of poor temporal consistency, unstable identity retention, and motion behavior issues. The best outcome is achieved by skillful design of the prompt in alignment with the current AI video models.